
推荐理由:笔者将焦点集中在对互联网在线垂直社区的内容挖掘上,并且利用了多种数据挖掘方法和商业模型,以汽车之家的口碑数据挖掘为例,进一步对Social Listening的分析方法和应用场景进行分析与阐述。
(

在笔者之前的文章《干货|如何利用Social Listening从社会化媒体中“提炼”有价值的信息?》中曾提到,Social Listening可以帮助企业实现如下图所示的几个商业目标,这引起了一些新媒体、咨询从业者浓厚的兴趣,他们强烈要求笔者继续对Social Listening的分析方法和应用场景做进一步的阐述。
作为回应,笔者将在本文中对该主题做进一步的延展,聚焦到对互联网在线垂直社区的内容挖掘上。在本文的第二部分,笔者将利用多种数据挖掘方法和商业模型,以一个实际案例来聊聊Social Listening是如何从垂直社区中挖掘出商业价值的。

一、分析背景:从互联网垂直社区的数据中“淘金”
1.1 垂直社区蕴含着更具商业价值的信息
从目前社会化媒体的发展格局来看,门户网站日渐式微,微博、微信、抖音等社交网络玩得风生水起。根据消费者的关系轻重来看,社交网络是由关系引发起讨论,因此讨论的时效性比较短,消费者的注意力也会比较分散;而垂直社区则是由兴趣引发话题和讨论,因此时效性较长,消费者粘性也较高。

从更深层次来讲,垂直社区和第一代大而全的综合性网站(搜狐、网易、新浪等)或包罗万象的社交网络(微博、微信、抖音等)不同,垂直网站将注意力集中在某些特定领域或某种特定需求,提供有关这个领域或需求的全部深度信息和相关服务。
最后,基于垂直社区内容的垂直搜索可以帮助消费者提高搜索信息的效率和质量。随着互联网消费者和网上内容的急剧增长,由通用信息源向专用信息源的过渡是很自然的。举个例子来说,某人如果想在Baidu或者Google上找个靠谱点的美容医院就像是大海捞针,因为搜索引擎上的广告多,且内容分布较零散,不容易找到符合消费者需求的专业信息。但是,如果直接在某知名的X氧网,情况可能会好不少,因为垂直搜索一下,大量专业机构、从业者和海量点评可供选择和参考。搜索领域有句明言:消费者无法描述道他要找什么,除非让他看到想找的东西。这个过程有点像找对象,“碰运气”是消费者搜索行为的最大的特征,而基于垂直社区的垂直搜索引擎就可以帮助消费者提升“运气”。
一言以蔽之,社会化媒体中的垂直社区是移动互联网时代的“宠儿”,沉淀有大量的优质且专业的内容,因而吸聚了大批用户,随之而来的是海量的UGC,这给Social Listening提供了可供挖掘的矿藏,从中提炼出改进产品、提升品牌价值的insight来。
1.2 各领域较知名的垂直社区
互联网流量也遵循“幂次法则”,即80%的用户(注意力)集中在20%的网站上,大量的用户UGC也集中在这小部分网站上,对于行业垂直社区而言,更是如此。
所以,笔者在做Social Listening的时候,特别关注头部的行业垂直社区,这些行业头部媒体/平台较为专业,拥有最多的、精准的目标用户群,分析上面的用户UGC能发掘出用户对产品的反馈和用户痛点,甚至可以由内容反推出目标人群画像,可谓是玩法多多。
以下是笔者梳理的若干有影响力的行业(移动)垂直社区,其中的UGC是Social Listening的重要分析信源:
旅游类:携程网、驴妈妈、马蜂窝、猫途鹰
汽车类:汽车之家、爱卡汽车
互联网技能类:人人都是产品经理、运营派
互联网资讯类:虎嗅、36氪、钛媒体
医疗美容类:新氧网、悦美网、更美网
摄影类:蜂鸟网
女性类:辣妈帮、她社区、美柚
母婴类:宝宝树、宝宝知道、妈妈帮
财经类:雪球、财新网
在线音乐类:虾米、网易云音乐
音频分享:喜马拉雅、蜻蜓FM
点评类:大众点评
……
除此之外,淘宝、京东、网易考拉海购等电商平台也纷纷开通了内容频道,针对不同的商品品类和人群打造内容生态,吸聚拥有特定需求的人群,这些都是极具分析价值的Social Listening信源。
下面,笔者将从X车之家上的口碑评论数据出发,利用各种数据挖掘技术,对凯迪拉克这个汽车品牌做产品反馈和品牌形象方面的挖掘分析,力求得出make sense的结论。
二、从凯迪拉克在汽车之家的口碑数据中挖掘出有价值的信息
2.1 数据获取
本文的数据获取来源为汽车之家。那为什么选择汽车之家作为分析对象呢?
汽车之家成立于2005年6月,成立至今已有14年的历史,它为汽车消费者提供选车、买车、用车、换车等所有环节的全面、准确、快捷的一站式服务,是基于汽车专业内容的垂直社区,是全球访问量最大的汽车网站。因此,它上面能集中大量优质的用户UGC,可以“倾听”到用户关于汽车及其品牌的“声音”。
在这里,笔者获取的是汽车之家上“口碑频道”的数据,是关于购车消费者买车后的评论。该频道提供的数据维度丰富,包括汽车各方面的评分及其文字评论、晒图,以及各帖子的互动数据等。
下图是一条口碑评论的截图,可以看到一条口碑评论由许多结构化和半结构化的数据维度组成:
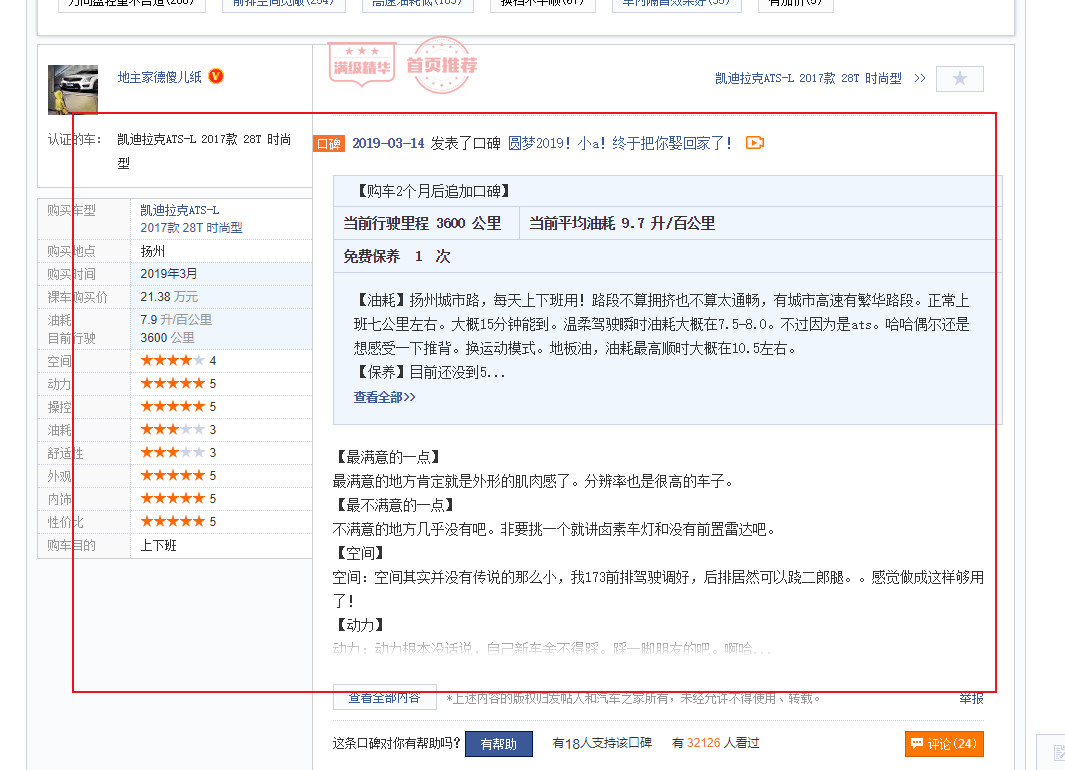
笔者在这里进行数据采集的根据是Python中的Scrapy,它是Python下的一个快速、高层次的web抓取框架,用于抓取web站点并从页面中提取结构化的数据。获取的数据对用户和帖子详情信息做了处理,不涉及到用户隐私,且本分析不作商业用途,仅供学习探讨。
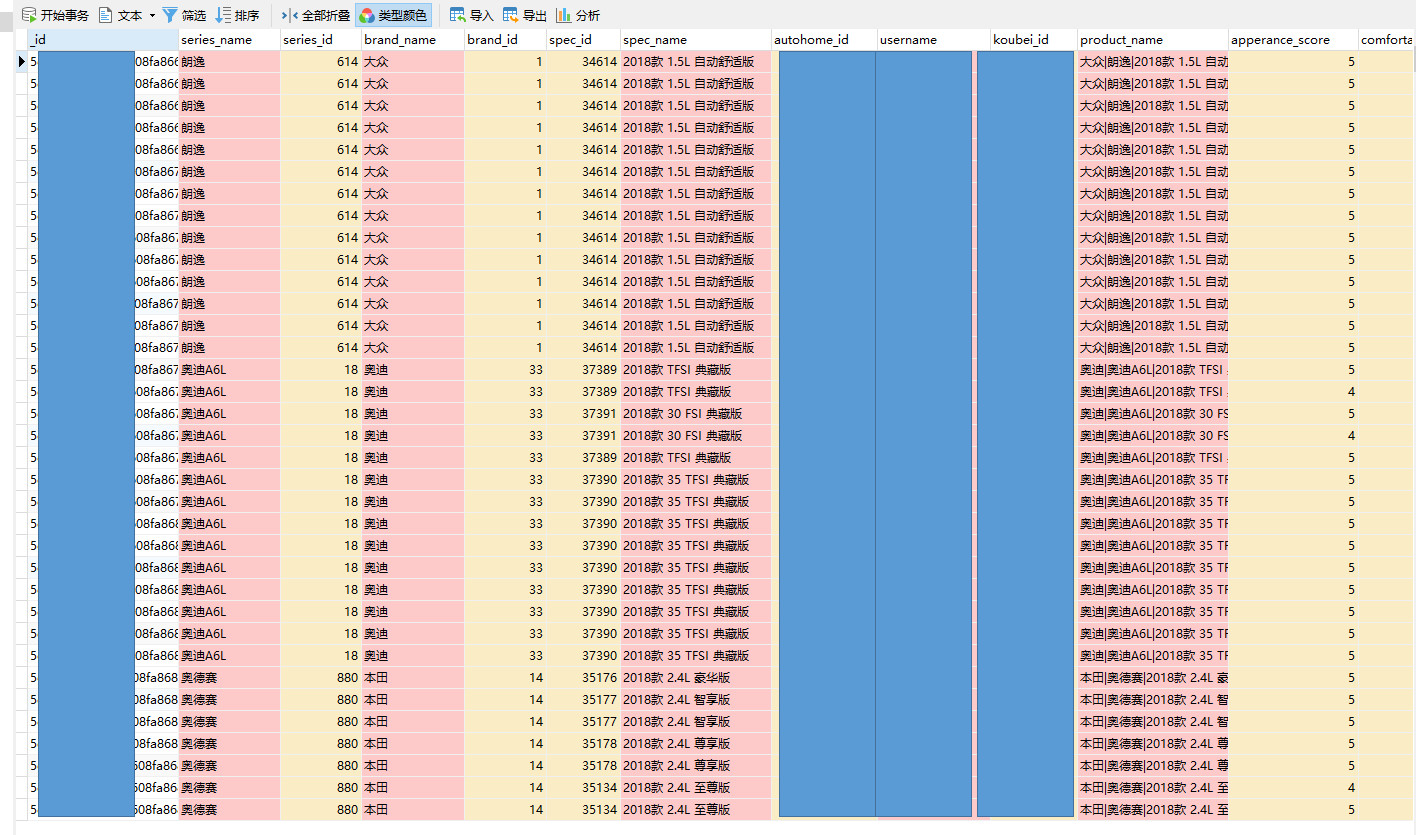
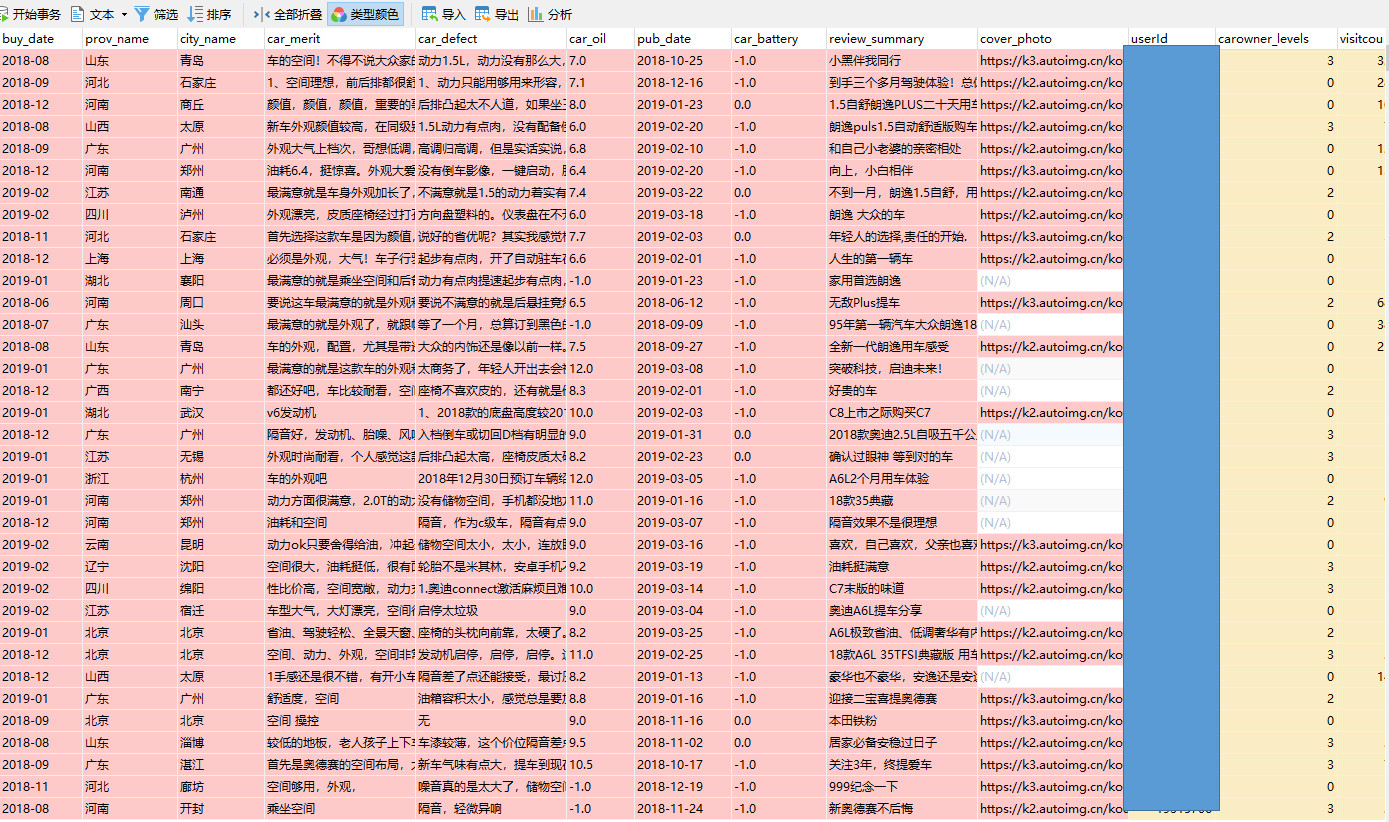
获取的口碑评论量为30w+,其中凯迪拉克下的评论有12,900条,存储在SQL SERVER2017中,以下是数据的存储效果:
2.2 分析目的
以下是笔者接下来分析挖掘的重点内容,主要集中在凯迪拉克的产品反馈和品牌调性方面:
1) 了解消费者的购车目的,从用途/使用场景角度进行分析
2)了解消费者的购车原因,从汽车的几个重要维度,如安全性,操控,动力,油耗等
3)了解消费者比较重要的购车因素,即用户比较关注哪些汽车功能或汽车器件
4)分析消费者眼中的品牌调性,与事先设定的品牌调性有何差异
5)在上述分析中加入竞品分析,分析异同点
2.3 数据特征及分类
现在,根据分析目的对获取到的数据的字段进行分类和挑拣,选择部分可作为分析的数据:
1)评级类数据:
comfortableness_score(舒适性评分)
internal_score(内饰得分)
maneuverability_score(操控性得分)
oil_score(油耗评分)
power_score(动力评分)
apperance_score(外观评分)
costefficient_score(性价比评分)
space_score(空间评分)
Satisfaction (满意度)
2)半结构化数据:
purpose (购车目的/用途)
bought_Address(购买地址)
brand_name (品牌名称)
buy_date(购买日期)
buy_price(购买价格)
carowner_levels(车主等级)
prov_name(省份名称)
city_name(城市名称)
Comment_count(评论数)
Helpful_count(有用数)
Visit_count (浏览量)
product_name(产品名称)
pub_date(发布日期)
3)文本类数据:
apperance_feeling(外观感受)
comfortableness_feeling (舒适性感受)
costefficient_feeling (性价比感受)
maneuverability_feeling (操控性感受)
internal_feeling (内饰感受)
power_feeling (动力感受)
oil_feeling (油耗感受)
space_feeling(空间感受)
car_defect(车辆缺陷)
car_merit(车辆优点)
review_summary (评论总结)
bought_reason (购买原因)
本文分析所用到的数据主要是文本类数据和小部分的半结构化数据。
2.4 消费者购车目的分析
在“消费者目的”分析中,笔者选取了宝马、捷豹、奔驰、凯迪拉克和路虎这5个汽车品牌作为分析对象,想要知晓消费者在这5个汽车品牌的使用场景上有什么不同,这也是汽车厂商较为关注的方面 — 自己的产品定位于消费者心智中的定位是否一致,宣传策略是否需要强化或者调整。
在口碑频道的评论中,存在“购车目的”这一字段,是一个半结构化的选项,评论者可以选填自己喜欢购买小车的应用场景,官方提供了10个候选项:
购物
接送小孩
拉货
跑长途
泡妞
赛车
商务接送
上下班
越野
自驾游
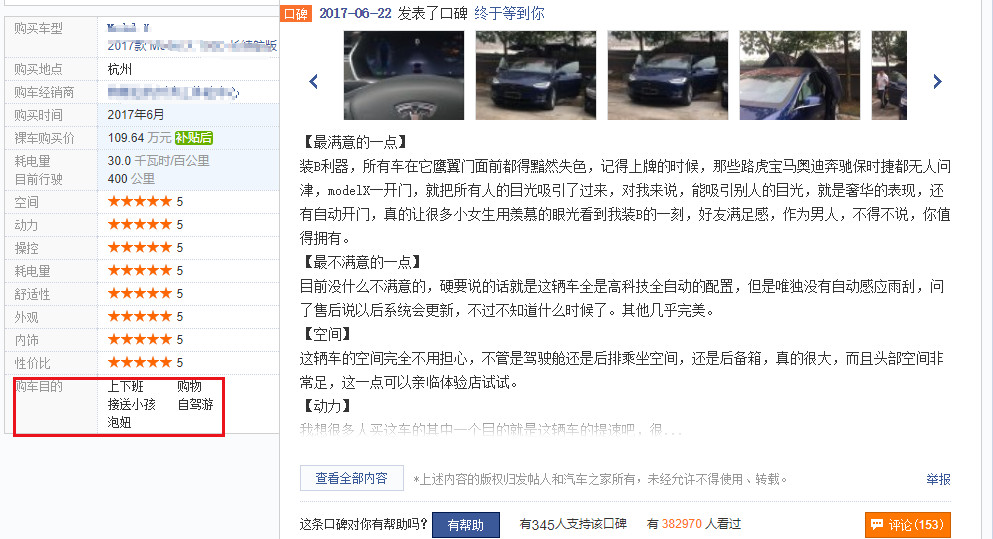
从上图中可以看到,消费者可以同时填写多个购车目的标签。所以,在正式分析之前,需要对该标签数据进行拆分,出现多个标签的行要拆解成多行,对结果进行透视表统计,最后整理成交叉列联表。结果如下表所示:
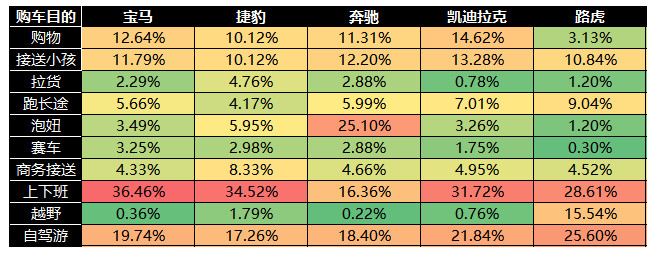
从上面的表格中,我们可以看到,宝马、捷豹、凯迪拉克和路虎这4个汽车品牌的主要购车目的是“上下班”,用于上下班通勤,而奔驰的主要购车目的集中在“泡妞”上,购车目的不单纯……
然而,上面的表格并没有完全挖掘出多元关联数据中的价值,此时该对应分析(Correspondence Analysis)出马了!
对应分析(Correspondence Analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表(也就是上表)来揭示变量间的联系,它可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系,是一种强有力的数据可视化技术 。
对应分析主要应用在市场细分、产品定位、地质研究以及计算机工程等领域中。原因在于,它是一种视觉化的数据分析方法,它能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。
对应分析的基本思想是将一个列联表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样例(这里是汽车品牌)和众多的变量(这里是购车目的)同时作到同一张图解上,将样例的大类及其属性在图上直观而又简洁地表示出来,具有直观性。另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样例进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
得到对应分析二维坐标图以后,要想作出正确的解读,还需要使用点“小手段”:
从坐标轴中心向任意汽车品牌连线(具有方向,是一条射线),指向汽车品牌的方向为正向,然后将所有的使用场景往这条连线及其正反延长线作垂线,(使用场景的)垂点越靠近该连线及其延长线的正向方向,就代表该使用场景对于该汽车品牌而言更常见。
下图是将上表数据映射到二维坐标系的可视化呈现(点击图片放大看高清大图):
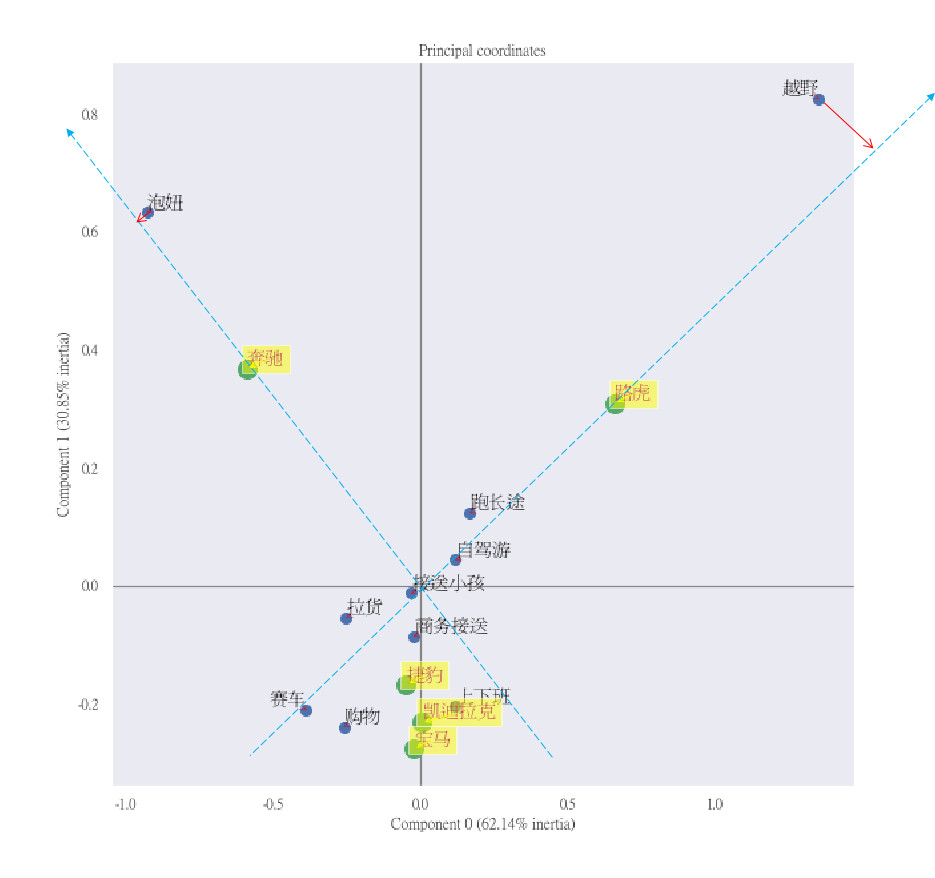
转换后的可视化结果更能发现一些有趣的事实:
捷豹、凯迪拉克和宝马从使用场景(购车目的为购物、上下班、商务接送、接送小孩等)上来说,几乎是重叠的,彼此是竞争对手;
奔驰最突出的使用场景还是泡妞(射线正向上离得最近),其他使用场景并不突出(在射线负向上);
路虎的越野特性还是最突出的,跑长途和自驾游的特性也较突出。
由分析的结果可知,凯迪拉克的使用场景比较泛,当然原因也有可能在于笔者分析的是品牌而不是具体的车系和车型,分析的粒度较粗,笔者将会在文末聊到这一点。
2.5 了解消费者关注的典型话题
这里,笔者将凯迪拉克口碑数据的两个字段 — Car_defect(车辆缺陷)、Car_merit(车辆优点)整合到一起,对评论内容进行一个“鸟瞰式”的分析,迅速识别出汽车消费者较为关注的话题。
此处的分析基于HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)实现。相较于K-means、Spectral clustering、Agglomerative clustering、DBSCAN等传统聚类算法,笔者特别欣赏它的3大特性:
不需要设定聚类数,有算法自动算出来簇群数
可以较好的处理数据中的噪音
可以找到基于不同密度的簇(与DBSCAN不同),并且对参数的选择更加鲁棒(Robust,模型更加健壮)
基于自动聚类形成的关键词词云,能自然的反映评论数据中的潜在结构和语义特征,由此能准确且清晰的知晓消费者对于汽车及其功能、器件的关注侧重点。
对于生成的可视化结果,可以这样解读:
字体大小表示词汇的权重值大小,注意,这里的权重非词频数,而是TF-IDF值,更能表示该词汇在评论中的重要性
颜色代表不同的话题
词汇之间距离越近,说明它们在同一语境中出现的频率较高,越具有语义相关性,比如“胎噪”、“轮胎”、“啃胎”、“噪音”、“隔音”等词汇挨得很近,我们能迅速联想到是胎噪导致噪音或者隔音效果差,而不是汽车发动机或者车厢内组件老化产生的摩擦声引起的。
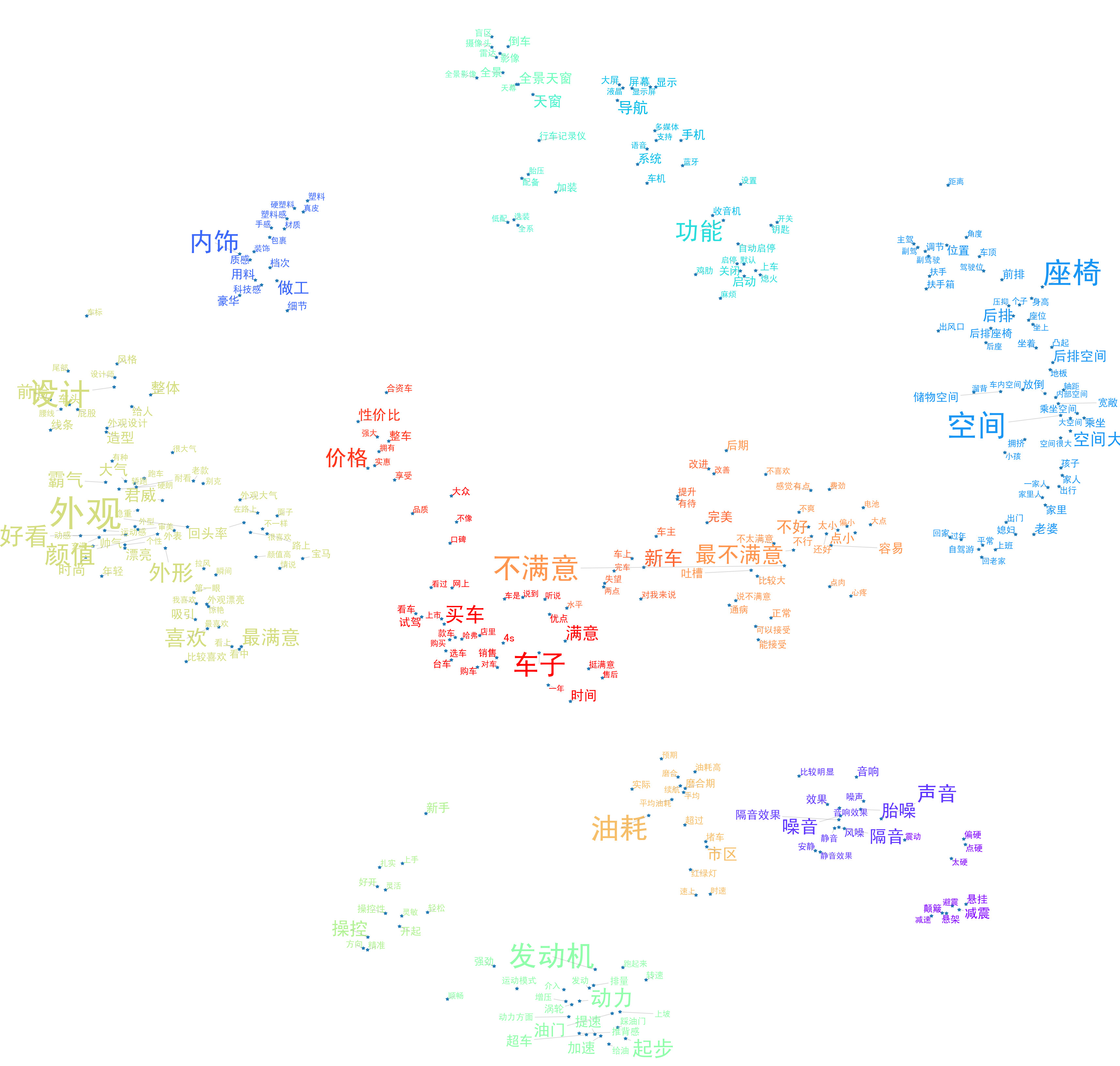
下图是自动聚类出来的结果,自动聚为12个主题:
为了将各主题的界限划分得更清晰些,笔者给每个主题加了虚线框(点击图片放大看高清大图):
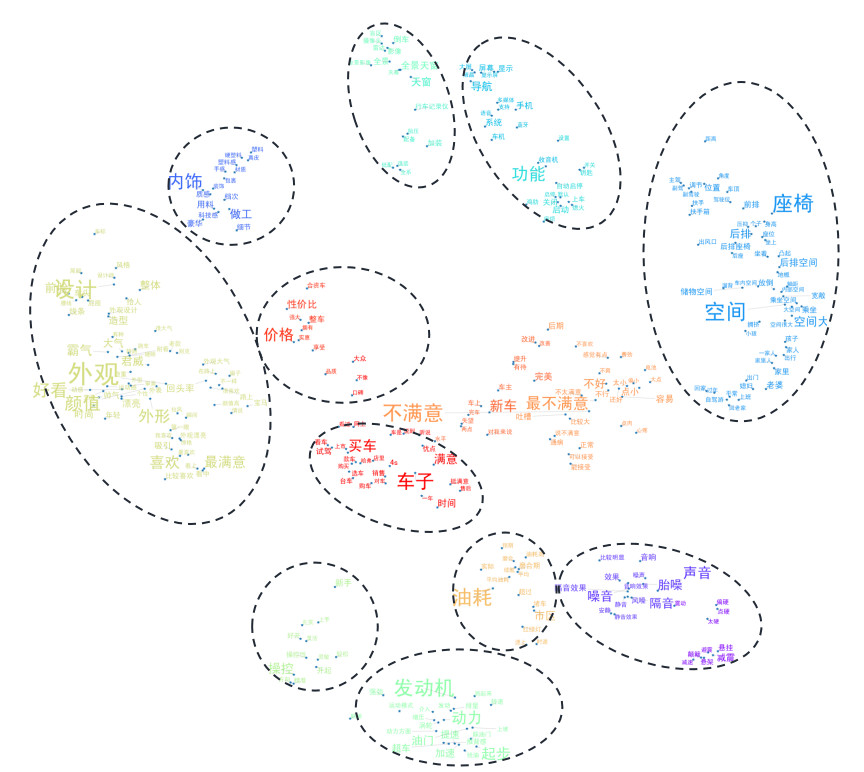
上图中,较为突出的是11个主题,按其重要性程度(字体大小、主题词数)选出TOP5,根据其中的关键词可以推测消费者的热门讨论内容,依次是:
外观:汽车的整体设计,主要是外形,买车的消费者大都是“颜控”
空间:后排空间、储物空间和后排座椅是大家比较关注的方面,另外,一家人出行的时候,空间问题就容易突显
动力:发动机、汽车起步(油门、起步)、提速/加速问题是动力这一主题下消费者较为关心的方面
配置:汽车配置这块,消费者对导航系统和内部的显示屏较为关心
内饰:内饰这块,消费者反映较多的是材质的塑料感
由于笔者不是汽车行业的从业人员,平时也不开车,所以对该领域的关键词不太敏感。不过,如果是这方面的从业者,根据词汇之间的关联性(距离远近),会有可能从总体上发现一些业务相关问题。
2.6 从“车辆缺陷”中识别凯迪拉克的重要产品缺陷
刚才的关键词云是一个“鸟瞰式”的分析,可以在较短的时间内抓住海量评论的重点。但是,如果我们想要进一步了解消费者对于凯迪拉克的哪些缺点比较关注,也就是挖掘消费者关于凯迪拉克的产品缺陷的典型意见,这就涉及到分析Car_defect(车辆缺陷)这个字段了。
这里,笔者想找到凯迪拉克的12,900条负面评价中最具代表性的差评,思路如下:
1)抽取语句中的主观性信息(形容词、副词、习语,反映消费者的评价),和客体信息(名词,主要是汽车各器件、功能、使用场景等,排除掉人名、地名、时间等实体)。
2)对每条评论中代表主观性信息和客体信息的词汇的TF-IDF值进行累加,得到每个评论语句的重要性得分。

3)对这些评论进行聚类,最终形成了10个规模较大的簇群,数量较少的被当做噪音处理,尽管它们具有一定的长尾价值。
4)在每个簇群中,找出重要性得分最高的语句,且词汇数限定在100个以内,字数太多,观点不明确,重点不突出,对于后续浏览者的影响力也有限。
以下是按照上述思路挖掘出的TOP10典型意见,代表了购买凯迪拉克的用户对于凯迪拉克车辆缺陷中的10个方面较为不满:
30多万的车标配的卤素大灯,没有前后雷达让人有点无语
提速没有传说快!倒车后视镜显示太模糊!A柱有点挡视线!
储物空间明显不够用 比起我家之前的小6子少太多,特别是手机完全不知道怎么搞
基本没有,硬要找的话可能是有时会有点异响
6AT确实老了点,算是够用吧。
最不中意的就是排挡杆,巨丑
暂时没有,再就是新车油耗有点高。漆有点薄,准备去做镀晶。
这个也不算是不满意吧,因为后轮驱动的原因,中间的隆起实在是有点影响乘坐,后备箱也因为这样子不是很大平时东西多的时候都要放在后座。
底盘确实硬一点,舒适度差了一点~
感觉这个车的音响效果并不如想象中的好。
上面这些典型缺陷可以作为汽车厂商接下来产品改进的重要考量。
对于“30多万的车标配的卤素大灯,没有前后雷达让人有点无语”这个典型观点,利用基于LSI的相似语句检索,可以看到最相关的若干信息,看看在这个话题下,用户具体的槽点和痛点是哪些:

2.7 从“购车原因”评论中挖掘凯迪拉克的优劣点
“购车原因”跟之前的“购车目的”还不一样,后者说的是消费者买车的使用场景,买车用来干嘛;而“购车原因”指的是汽车品牌的某些方面(比如外观、动力、油耗等)对消费者有强大吸引力,从而促成下一步的购车行为。对于本部分分析,笔者用到的是口碑数据中的Bought_reason(购买原因)字段,它一般出现在口碑评论的最后一部分,如下图所示:
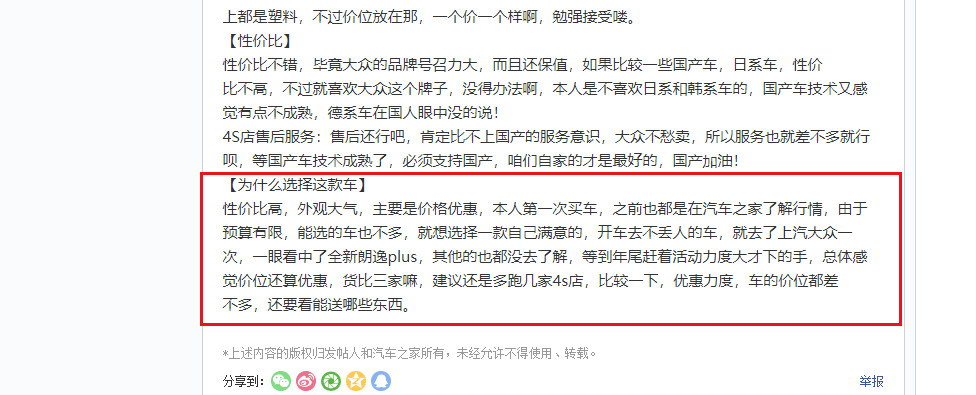
值得注意的是,该部分的分析要比之前的购车目的分析困难不少,原因在于:
该部分仅有评论,没有结构化或半结构化的标签,不便于统计分析;
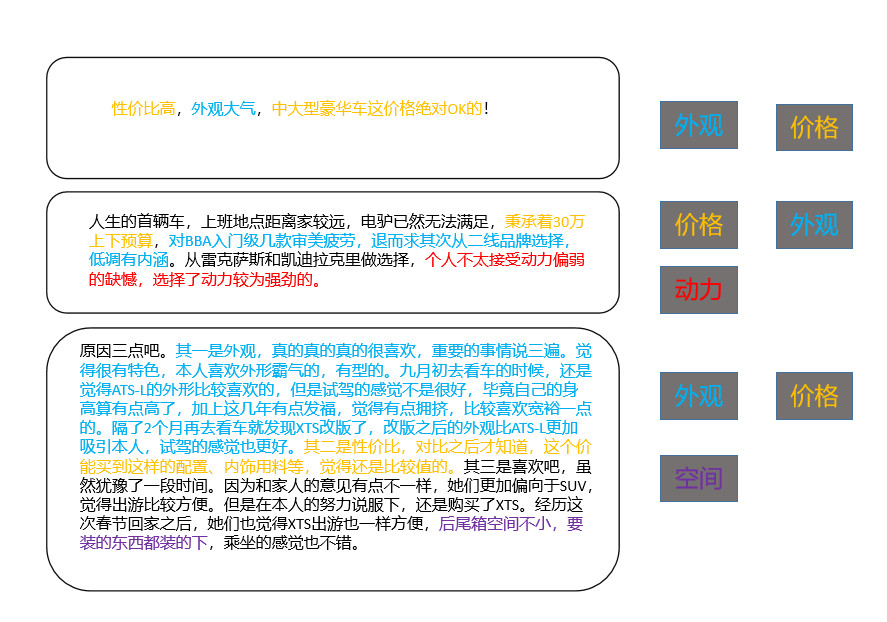
如果需要给评论打标签的话,促使消费者买单的原因往往不只一个,比如消费者买车可能是因为汽车的油耗低、动力强劲及性价比低,这就是一个多标签分类问题了。
具体情形,如下图所示:
鉴于此种情况,笔者采用基于机器学习的文本多标签分类(Multi-Label Classification)模型。要提高本模型的预测效果,除了要做好文本预处理,同时也要在模型的构建中充分考虑标签之间的关联性,采用融合模型,再用GridSearchCV找到最优参数,如此才有可能获得较好的预测效果。
用于训练模型的评论有7,000条,用于测试模型效果的评论有3,489条,模型的评估结果如下图所示:
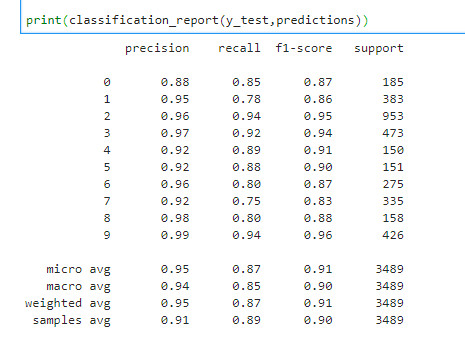
可以看到,该模型的准确率、召回率以及FI Score尚可,在实际的文本挖掘中基本可用。下面用训练好的文本多标签分类模型对凯迪拉克的Bought_reason(购买原因)下的每一条评论的标签进行预测,结果如下图所示(点击图片放大看高清大图):

将预测的结果保存到csv中:

注意,上述结果中,有些评论不在已有的标签范围内,比如“没办法,买奔驰就是为了装X,泡妹子,购车愉悦指数120!”,对于这种情况,返回的是空值。如果要得到更为精确的结果,就需要人工标注大量数据,再次训练分类模型,这就是另一个问题了,不在本文的讨论范围之内。
跟之前分析“购车目的”的方法一致,先构建交叉列联表,然后再绘制对应分析图,结果如下:
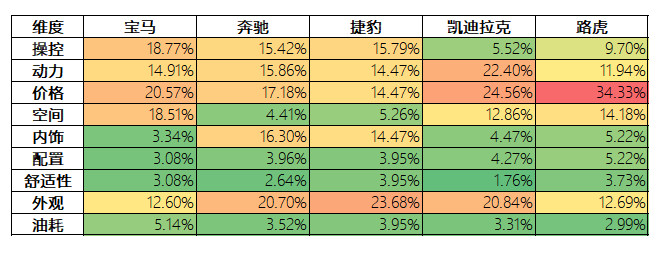
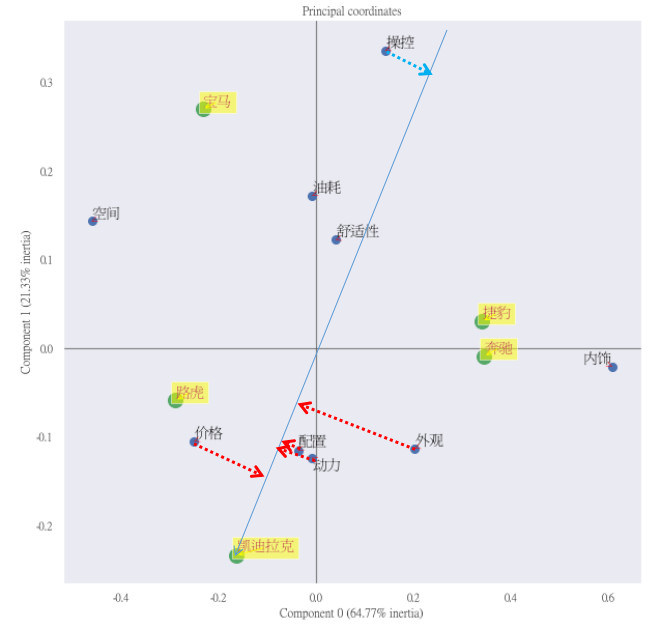
从上图的垂点距离射线“坐标轴中心—>凯迪拉克”正向方向的远近可以看到,消费者购买凯迪拉克的主要原因在于它的价格优势,也就是性价比高,其次是动力和配置,这些都可以看做是凯迪拉克在市场上的优势。由于“坐标轴中心—>路虎”这条射线和“坐标轴中心—>凯迪拉克”射线的夹角最小,所以它们的优势趋同。同时,在射线“坐标轴中心—>凯迪拉克”负向方向的末端,可以看到操控是购买诱因中最弱的一项,由此可知,与其它4个竞品相比,凯迪拉克的操控性能还有待提高。
“操控性”即汽车的操纵与控制性能。我们在驾驶汽车时的操控行为无非是加速、制动、转向。如果要看到消费者关于操控性能的具体“槽点”在哪里,可以针对Maneuverability_Feeling (操控性感受)这个字段进行典型差评查找,好奇心又驱使笔者去查了一波:
这车的操控不好与同价位的轿车相比,另外原来要买铬灰米内,厂家不排产米内,浪费我一个月,比较生气, 0.942013
太大了,转向不太灵敏,对于我这种手法不好的人不太友好, 0.6233139
悬挂太硬,过沉降路段体验不好,甚至于惊险, 0.511822
才提车买发现太多缺点,有一点就是它比我以前开的锋范大太多了,停车有时候不好停,上次还因为车身太大,被擦过一次保险杠,以后过了首保再来说说吧,0.34865487
2.8 从“购车原因”中挖掘出重要的购车影响因素
在这部分分析中,笔者将所有文本类字段进行合并,做进一步文本挖掘,看看具体是哪些因素诱发消费者购买凯迪拉克的。笔者的做法是,从每条语句中抽取TF-IDF最高的TOP15关键词,主要是汽车实体词(描述汽车零部件、特性、配置相关的词汇)、功能或者评价词。

然后按词汇顺承关系(时间先后顺序,箭头指向方为向后提及)做词汇共现分析,去词频数较高的若干词汇,最后形成下图(点击图片放大看高清大图):
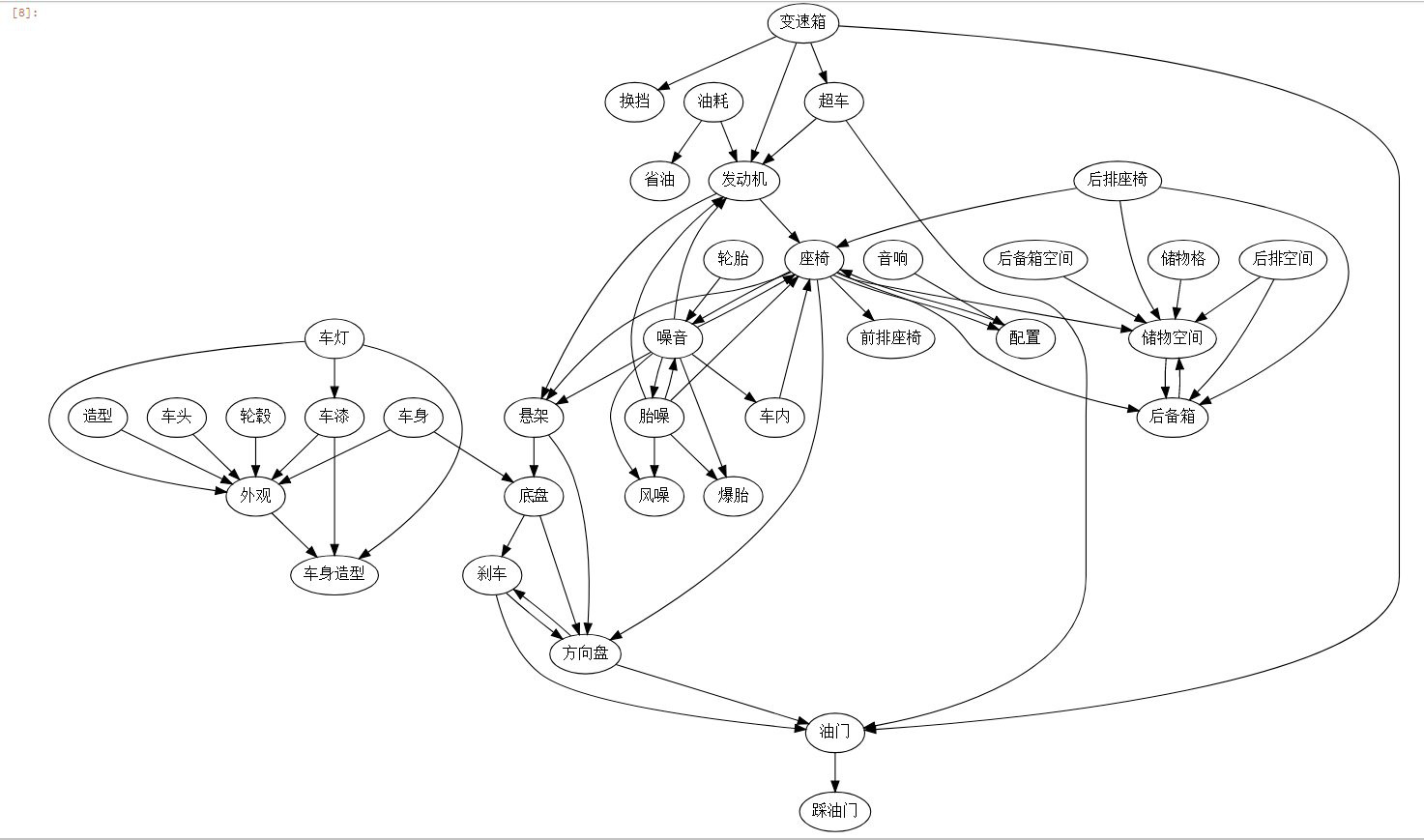
从上图可以看到,外观、座椅、储物空间、发动机、方向盘、后备箱是凯迪拉克购车者较为关注的方面,至于是好的评价还是差的评价,现在还未可知。这些关键词节点的“Betweenness Centrality (中介性核心性)”较高,该词学术的解释是“两个非邻接的成员间的相互作用依赖于网络中的其他成员,特别是位于两成员之间路径上的那些成员,它们对这两个非邻接成员的相互作用具有某种控制和制约作用“,在评论中经常与其它汽车器件共同出现,说明这些器件是购车者较为关注的方面。如果想看到消费者关于这些器件的具体看法,可以采用上述LSI检索相关的语句,笔者在这里就不做赘述。
2.9 基于微博数据的消费者兴趣挖掘
了解消费者的兴趣爱好对于打造品牌调性、营销内容创作及投放渠道选择都有帮助,是产品市场调研和竞品分析中的重要事项。
这里,笔者先挖掘出汽车品牌对于人群的兴趣图谱,然后结合使用与满足理论(Uses and Gratifications)对结果进行解读,为内容创作和媒体投放方面提供方向。
对于消费者的兴趣爱好的挖掘,笔者会用到新浪微博的消费者个性标签数据。该部分数据基于关键词命中,也就是说,采集到的标签数据仅针对提及目标汽车品牌的微博用户。
在这里,笔者采用的标签数据涉及到5个品牌,即凯迪拉克、宝马、奔驰、路虎和捷豹,时间跨度为近一个月。
数据预处理方式跟前面的一致,最终得到如下对应图谱:
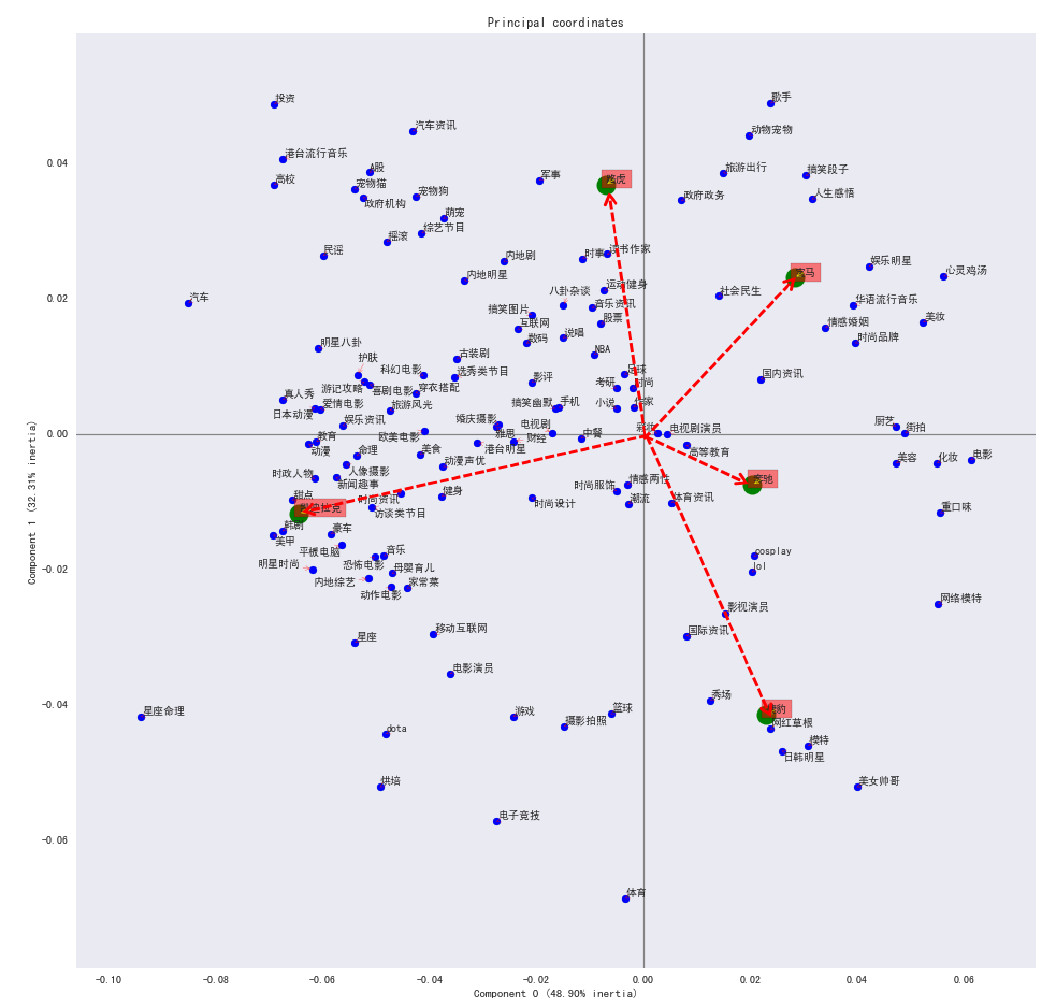
比照之前对应分析图谱的分析方法,我们可以得到与各个汽车品牌典型且最为接近的微博消费者兴趣标签:
凯迪拉克:星座命理、汽车、美甲、韩剧、内地综艺等
宝马:心灵鸡汤、歌手、娱乐明星、搞笑段子、人生感悟等
奔驰:美女帅哥、网络模特、模特、重口味、网红草根等
路虎:投资、汽车资讯、歌手、旅游出行、A股、军事等
捷豹:体育、美女帅哥、电子竞技、日韩明星、模特等
可以看到,这几个汽车品牌的关注人群的兴趣大体上都呈现娱乐化的特点,影视、明星方面的兴趣较多,这也与微博娱乐化的平台特性有关。
挖掘出汽车品牌所对应人群的兴趣爱好以后,可以采用使用与满足理论(Uses and Gratifications)对结果进行深度解读和应用。
使用与满足理论是一种以受众为中心的理论,侧重于对大众传播的理解。虽然其理论框架来自传统媒体,并远远早于互联网和社会化媒体,但其理论假设使其完全适用于互联网和社会化媒体研究。该理论假设可以概括为:
在选择媒体和内容时,受众是积极的参与者,会根据个人目标选择媒体和阅读倾向;
媒体渠道彼此之间竞争,还与其他资源竞争,以获得受众的关注;
人们在选择媒体和内容时,是主动、自我清醒且受动机驱动的,这使得他们能够清楚的表达选择媒体的原因。
基于这些假设,该理论认为受众会积极的寻求满足,而满足的类型将推动他们对社会化媒体及内容的选择,因而媒体选择是目标导向和实用驱动的,也就是受众的需求要被所选择的社会化媒体满足。满足类型背后往往潜藏着更为个性化的内在需求,E·卡茨、M·格里维奇和H·赫斯将其归纳为5个大类:
1. 认知需求——获得信息、知识和理解,如上知乎提问或者浏览感兴趣的话题、母婴论坛找育儿知识等;
2. 情感需求——情绪的、愉悦的或美感体验,如快手、抖音上看美女直播;
3. 个人整合需求——加强信心,稳固身份地位,如通过加入线上圈子,观察同类的言行,并通 过这种方式获得身份认同;
4. 社会整合需求——如利用即时通讯软件与熟人或生人进行交流,发展或维护人际关系;
5. 舒解压力需求——逃避或转移注意力,主要是娱乐活动,包括各种网游和对战游戏。
利用使用与满足理论对上述各汽车品牌的兴趣标签结果进行分析,大体上可以得出如下结果:
凯迪拉克:舒解压力需求
宝马:舒解压力需求、情感需求
奔驰:情感需求
路虎:个人整合需求
捷豹:舒解压力需求、情感需求
上述结果反映了各汽车品牌用户在媒体选择时的内在需求,在内容制作和媒体选择时可以作为参考。比如,凯迪拉克可以选择舒解压力需求的内容频道或者社会化媒体(比如即刻、一条等,举个例子,不是打广告哦),内容制作上可采用游记类主题,音乐可以采用舒缓的轻音乐,图片风格则是小清新…
当然,上述兴趣标签还可以有另一种用途 —利用Censydiam消费动机模型挖掘汽车品牌消费者进行消费时的情感驱动因素。详情可参看笔者之前的文章《当数据分析遭遇心理动力学:用户深层次的情感需求浮出水面(万字长文,附实例分析)》。
此外,从竞品分析的角度,对应分析图还可以作如下解读:
向量的夹角大小:
从向量夹角的角度看不同品牌之间的相似情况。上图中任意两个汽车品牌向量之间的夹角越小,代表这两个汽车品牌的消费者兴趣爱好相近,实际上反推出品牌调性的趋同。这里可以看到,奔驰和捷豹的在微博上的关注人群的兴趣爱好趋同,由此反推出品牌调性较为接近。凯迪拉克和其他4个汽车品牌之间的品牌调性差异较大,个性较鲜明。
距离坐标轴的远近:
从统计学上来看,品牌越靠近坐标轴中心,越没有特征;越远离坐标轴中心,说明特征越明显。
从品牌角度来考虑,说明越远离中心的汽车品牌,消费者越是容易识别,说明品牌特征(特点、特色)很明显;越靠近中心的品牌,消费者越是不容易识别,要说明品牌定位有问题,没有显著的特征可以识别,差异化还不够。从这一点来看,凯迪拉克和捷豹的品牌个性较为鲜明,奔驰的品牌定位最为模糊。
了解了品牌在潜在消费者心中的品牌形象以后,如果发现跟预期接近,继续加强这方面的投入即可,如果发现偏离预期,就需要及时调整思路了,在社会化媒体平台上发布能反映品牌调性的内容,引发关注人群的互动,长此以往,可以对塑造特定的品牌印象起到一定帮助。
2.10 基于评论内容的品牌调性挖掘
现今这个消费时代,消费者的消费模式逐步从实用主义消费过渡到象征性消费,从仅注重产品的功能和质量,转变为更注重品牌与自身品位、气质的契合度,从这个方面来讲,品牌越来越成为消费者的自我延伸。
与此同时,与早期产品和品牌宣传事实信息、功能化描述及产品诉求不同,强调品牌调性的情感式营销聚焦于产品、服务和品牌的“人格化”因素,展现品牌的“人性化特征”逐渐成为社会化媒体语境下强化传播和建立关系的主要手段,更为人性化的积极互动在社交媒体体验中的重要性越来越突出。
如果品牌与追随它的消费者保持持续的“人性化交流”,那么,相对于硬性推销方式,这种注重消费者关系维护的营销方式更能打动消费者,同时也能够鼓励消费者积极参与并长期追随。
为营造消费者与品牌之间积极互动的条件,品牌必须不断采用“拟人化”的方式来进行营销传播,使品牌具有人的性格和气质,这就涉及到“品牌调性”的话题了。
比较常规的做法是,品牌会用“拟人化”的方式在社会化媒体上去宣扬产品和服务的独特品质,这种方式可能是活泼的,也可能是清新的,抑或是高贵的…总之,品牌会着力打造一个属于自己的品牌个性和风格,从而与消费者在情感上产生联结,催生出大量拥簇。

然而,品牌所创造的品牌调性是通过各类媒介及内容呈现的,其中的重要信息随着表现的形式或者传播层级的递增而消减,最终反馈到消费者脑海中的可能是另一番景象,可能会产生一定的品牌个性认知偏差。因此,品牌运营者需要经常性的进行消费者品牌调性印象调研,及时了解消费者对于品牌个性的认知情况,视理解偏差的程度进行调整或优化。
在本文中,为了测量消费者对于凯迪拉克的品牌调性的实际认知情况,笔者采用千家品牌实验室改良过的品牌个性模型。千家品牌实验室向忠宏近六年来对20个行业领域1000多个品牌的持续监测与品牌个性的分析,提取出一些中国本土化的品牌个性词汇,这些新增的品牌个性语汇对应的品牌人格通过合并到三个品牌层面,最终也并入了Aaker提出的品牌个性的五个维度中。

下面是笔者进行品牌个性挖掘的实际步骤:
1)将凯迪拉克口碑数据中的所有文本类数据(外观感受、 舒适性感受、性价比感受、操控性感受、内饰感受、动力感受、油耗感受、空间感受、车辆缺陷、车辆优点、评论总结、购买原因等)进行合并;
2)经过自然语义分析,即“实体/属性—情感词”抽取分析,得到7035个“物件词+情感词”组合:
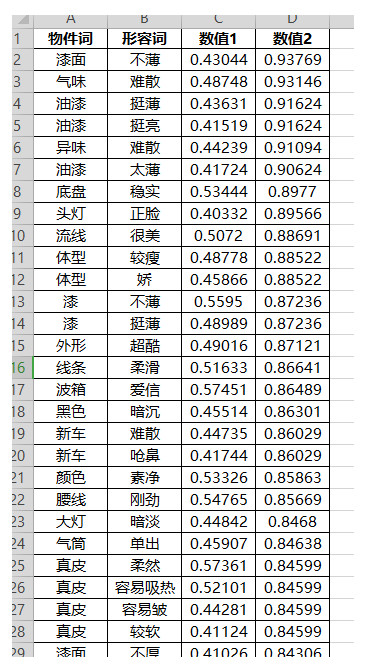
3)去除掉功能性的形容词,保留跟品牌调性相关的情感词。剔除掉描述汽车器件及功能的形容词,如“漆面+不薄”、“起步+很肉”、“气味+难散”、“真皮+柔软”等,其中的观点词/形容词对于描述品牌个性意义不大,而要保留拟人化的观点词,如“腰线”+“刚劲”中的刚劲,“体型+娇”中的“娇”;
4)根据品牌个性维度语汇库,对保留下来的品牌调性形容词进行归类统计。结果如下所示:

5)对统计结果进行旭日图可视化呈现,反映2个层级的品牌调性占比关系。结果如下图所示(点击图片放大看高清大图):
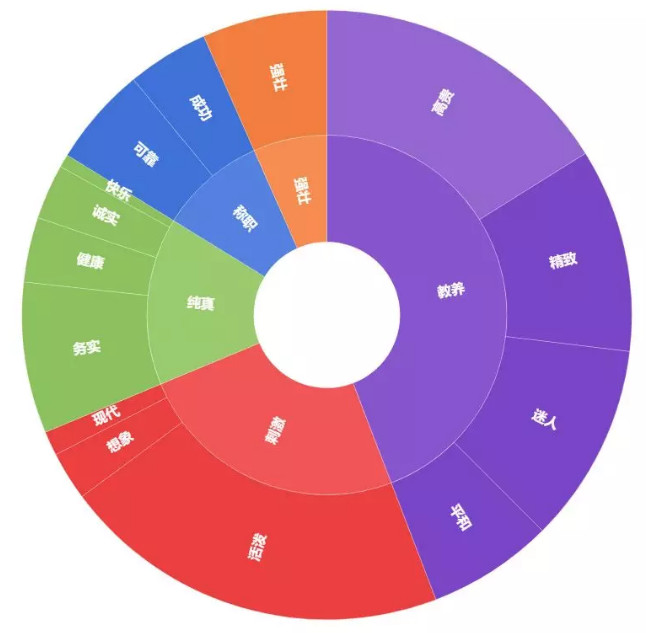
从最终结果可以看到,凯迪拉克的品牌调性偏于教养,主要在于高贵、精致、迷人的气质;其次是其“刺激”的一面,主要在于其活泼的个性。
我们不妨从百度百科上的凯迪拉克品牌史概略来看待这个结果:
“一百多年来,凯迪拉克汽车在行业车内创造了无数个第一,缔造了无数个豪华车的行业标准;可以说凯迪拉克的历史代表了美国豪华车的历史。在韦伯斯特大词典中,凯迪拉克被定义为“同类中最为出色、最具声望事物”的同义词;被一向以追求极致尊贵著称的伦敦皇家汽车俱乐部冠以“世界标准”的美誉。 凯迪拉克融汇了百年历史精华和一代代设计师的智慧才智,成为汽车工业的领导性品牌。
一款美国汽车可以很狂野,也可以很豪华,但是如果想要很尊贵就比较难了。不过卡迪拉克就是一个例外,他的创始人为了纪念底特律的奠基者、法国贵族安东尼凯迪拉克,就将其家族的徽章作为了车标。现在的卡迪拉克车标已经有了很大的变化,比如少了象征着三圣灵的黑色小鸟和镶嵌着珍珠的王冠,只是由桂冠环绕着经典的盾牌形状,而盾牌形状则由各种颜色的小色块组成,其中红色代表勇气,银色代表纯洁的爱,蓝色代表探索。”
如此看来,挖掘的结果较能反映事实情况,与品牌发展历程相符。
结合使用与满足理论和品牌调性分析,可以对于内容的规划、制作,以及渠道的投放提供参考,辅助决策。比如,分析汽车品牌跟网红的调性以及粉丝群体是否契合,找到合适的品牌代言人。
最后再来一个稍微扯淡点的分析,让思路再飞一会儿~
2.11 基于语义相关性搜索的品牌形象联想
接着前面的分析,假如我们想着力打造上述品牌个性中的某个方面,比如凯迪拉克想突出“现代”的调性,那我们该如何去操作呢?
首先,我们得有思路 :结合品牌所附着的产品特性和策划者的意愿,找到通向目标品牌调性的那条“认知链条”,即说服消费者接受品牌个性的内容要符合消费者的认知规律,符合逻辑。
在这里,笔者利用基于预训练词向量模型的语义相关性搜索,从154,800(12个文本数据字段*12900条凯迪拉克相关的口碑评论 )条汽车评论中挖掘出品牌和目的品牌调性之间的最短认知关联路径,用科学的方法发掘出构建品牌调性认知路径的线索。
这样说起来太抽象,笔者举一个实际例子来说明吧,比如我们想找到’原始森林’到’凯迪拉克’的认知路径,基于中文维基百科这个语境,结果如下:
print (morph(‘原始森林’, ‘凯迪拉克’))
原始森林–>自然保护区–>野生动物–>野生–>马鹿–>棕熊–>野性–>野马–>克莱斯勒–>凯迪拉克
从上面的结果可以看出,如果偏要将原始森林和凯迪拉克建立关联,最合理(同时也是最短)的路径就是中间这块【自然保护区–>野生动物–>野生–>马鹿–>棕熊–>野性–>野马–>克莱斯勒】。
上述是基于维基百科的语境得出的结果,接下来是基于154,800条汽车评论数据,做3个跟品牌调性联想路径挖掘。
print (word_morph(‘凯迪拉克’, ‘活泼’))
凯迪拉克–>XT5–>XTS–>凯迪–>承袭–>无余–>展露–>中正–>素雅–>雅致–>高雅–>活泼
print (word_morph(‘凯迪拉克’, ‘精致’))
凯迪拉克–>汉兰达–>中级轿车–>最出色–>百里挑一–>出众–>精密–>精美–>精致
print (word_morph(‘凯迪拉克’, ‘迷人’))
凯迪拉克–>独树一帜–>标新立异–>前卫–>曼恩–>棱角分明–>线条美–>妖娆–>销魂–>迷人
上面的标记颜色的词汇是比较有意义的“线索”,可以以此展开联想,发挥创意,进行内容创作。
结语
笔者在进行社会化媒体数据挖掘的实操中,有如下2点思考:
1. 分析粒度的问题
在本文中,笔者是从品牌的角度进行分析,粒度还是粗了些,因为不同的品牌会针对不同的受众开发不同的车系/车型,混杂在一起分析出来的结果会比较混杂,尤其是品牌定位这块会不精确。
理想的做法应该针对具体的series_name(2017款28T时尚型、2017款28T技术型、2018款28E四驱技术型、2018款28E四驱铂金版),或是spec_name(2017款 28T 时尚型、2017款 28T 技术型、2018款 28E 四驱技术型、2018款 28E 四驱铂金版),这样去做分析,指向性更强一些,结论更加鲜明。
2. 水军或虚假信息的问题
笔者之前在网上检索汽车之家的相关讯息时,发现一些读者戏称其为“水军之家”、“软文之家”,部分读者觉得上面的信息“人工凿痕”较明显,各大厂商为了宣传自己的新车无所不用其极。

僵尸横行,水军泛滥,作假成风,在这种情况下,社交媒体数据挖掘还有意义吗?
在笔者看来,是有的。
2018年10月份,麻省理工学院的Zakaria el Hjouji, D. Scott Hunter等学者发表了《The Impact of Bots on Opinions in Social Networks》,该研究通过分析 Twitter 上的机器人在舆论事件中的表现,证实了社交网络机器人可以对社交网络舆论产生很大的影响,不到消费者总数1%的活跃机器人,就可能左右整个舆论风向。
麻省理工学院研究组的这项工作,最大的发现是,影响社交网络舆论所需要的机器人,其实是很少的。少数活跃的机器人,可以对网络舆论产生重大影响。
虽然社交媒体机器人不会带来物理威胁,但它们却可能有力影响到网络舆论。在微博里,各类水军已经经常出现在营销造势、危机公关中。虽然你能一眼识别出谁是水军,但仍然可能不知不觉地被他们影响。
这些机器人看似僵尸,发起声来,比人类响亮得多,可能只要几十个几百个就足够扭转舆论!
所以,从社会化媒体数据挖掘的角度来看,信息的真实性并不重要,只要文章、帖子或者评论能影响到浏览者或受众,具有一定的(潜在)影响力,这类社媒数据数据就值得去挖掘。
更进一步说,跟销售数据反映消费者决策价值、搜索数据反映消费者意图价值相比,虽然社会化媒体文本数据的价值密度最低,好比是蕴藏金子和硅、却提炼极为困难的沙子,但由于它在互联网领域的分布极为广泛,且蕴含着对客观世界的细节描述和主观世界的宣泄(情绪、动机、心理等),其最大价值在于潜移默化地操控人的思想和行为的影响力,通过社会化媒体挖掘,我们可以得到对目标受众具有(潜在)影响力的商业情报。淘沙得金,排沙简金,最终得到的分析结果用以预判受众的思考和行为,为我们的生产实践服务。

此时,先贤Marcus Aurelius在《沉思录》中那句名言在耳畔响起,仿佛他在2000多年前就已经预言到我们所面临的困境:
Everything we hear is just an opinion, not the fact;Everything we see is just a perspective, not the truth.
我们所听到的一切,只是人们的主观意见,并非客观事实;我们所看见的一切,只是事物的冰山一角,并非本来真相。
参考资料:
数据来源:汽车之家口碑频道,2016.05-2018.12 ;新浪微博,2019.04 – 2019.05
数据处理和分析工具:Excel、Gephi、Python
苏格兰折耳喵,《数据运营|数据分析中,文本分析远比数值型分析重要!(上)》
苏格兰折耳喵,《在运营中,为什么文本分析远比数值型分析重要?一个实际案例,五点分析(下)》
苏格兰折耳喵,《干货|如何利用Social Listening从社会化媒体中“提炼”有价值的信息?》
苏格兰折耳喵,《干货|作为一个合格的“增长黑客”,你还得重视外部数据的分析!》
苏格兰折耳喵,《以《大秦帝国之崛起》为例,来谈大数据舆情分析和文本挖掘》
苏格兰折耳
苏格兰折耳喵,《文本挖掘从小白到精通(三)—主题模型和文本数据转换》
苏格兰折耳喵,《文本挖掘从小白到精通(四)—文本相似度检索》
TZ橘子,简书,《如何进行品牌形象定位分析?》
集智俱乐部,虎嗅,《MIT研究组:别瞧不起僵尸粉,它们真能左右舆论》
Zakaria el Hjouji, D. Scott Hunter, Nicolas Guenon des Mesnards, Tauhid Zaman,《The Impact of Bots on Opinions in Social Networks》
Hiroshi Ishikawa 著,郎为民 译,《社交大数据挖掘》
百度百科词条.对应分析
百度百科词条.凯迪拉克标志
百度百科词条.品牌个性
百度百科词条.垂直网站
使用与满足理论.MBA智库百科
黄善晴,微信公众号【腾讯大讲堂】,垂直社区产品:如何把相类似的用户都聚集起来?
傅瑞栋,站长之家,《移动互联网:论坛已死,社区新生》


